网站数据分析-对网站进行AB测试、多元测试
添加时间: 2012-10-26 点击:0
网站进行版面调整,哪一个方案看起来更好一些呢?在选择某一个方案上是相当矛盾的,如何把握各个方案效果的平衡,恐怕是个主观判断。AB测试仍然是改善效果最简捷有效的手段,但越是简洁的测试,所忽略的要素也就越多,所有成功都是有代价的。所以,充分关注B版的多样性,注意网罗回收那些从A版里掉出去的资源,我想也是长期优化所应该关注的一个环节。历来,AB 测试是搜索营销管理员非常喜欢的一种优化手段,但这并非SEM乃至在线营销的专利。本质上这就是可控实验:如果我们想针对SEM管理中的某个因素优化,就必须保持其他因素恒定以过滤掉可能的干扰。举个具体的例子,在SEM管理中最常使用的一种AB测试是广告词测试。同一系列的同一分组中同时投放广告词A与 广告词B,两则广告轮流展示(even rotation),那这两则广告得到的展现几率是大致相当的。

recommend版本广告词内容

recommend_20121023版本广告词内容
近似的展现几率下,recommend和recommend_20121023版广告词如果表现出了访客数与转化数的差异,我们就可以判定哪一条广告词更好。

两个不同的版本与访客是否浏览了新闻内容(news page)与产品内容(product page)的转化
判定以后,我们砍掉表现不好的广告词(比如recommend_20121023),然后加入一条新的广告词recommend_20121023,重新开始一轮AB测试。我们可以不断地进行这样的测试,直到我们确信在运行的广告词是最好的。
当然,测试内容不局限于广告词,可以是到达页面,可以是URL。测试也不需要局限于一个分组内,可以是系列,可以是目标市场,可以是转化路径,也可以是 Offer。这是非常简单的测试,然而是很有效的优化手段。如果你是一个搜索营销管理员,暂时觉得手头没有什么事情可以做的话,说明你懒惰了。因为你永远 都可以做些AB测试来深入优化。
一个电子商务的建网站客户做条幅广告转化率的测试,但我们发现数据有问题:我们需要知道有多少人点击了测试广告,以及有多少发生了购买。
我们的解决方案是添加一些新的代码,来确定谁看到了什么,让 phpstat Analytics 里的群体来实现这一方面数据的监控。通过这种方法我们能够更全面的了解任何给定测试,更准确地确定投资回报率。
A/B测试
添加代码之前我们先回顾一下测试样本的背景。你运营的是一家销售耳机的网站,现在想要测试下某新款高端耳机的两版本的首页。你用A/B实验来换掉了原先的首页,重要的是获得尽可能多的收入。
将消费者体验简化后看起来会是像这样的路径:

在 phpstat Optimizer 中我们只能选择一个A点和一个B点,我们无法跟踪整个渠道中客户的路径。这就是我们努力要克服的障碍。如果只是单一点到点的的跟踪,我们只能选择以下项目 之一来衡量:
访客是否有点击条幅广告?
访客是否添加产品到购物车?
访客是否发生购买行为?
但事实上没有哪个一个单一的转化能说明全部问题,我们需要更多信息。
开始动手
我们的目标则是建立一个可以跟踪所有路径的易用系统,帮助我们确定会在哪个环节流失客户。在这里,要强调一点,系统不需要相关的技术人员参与代码的编写,系统会自动根据用户的选择,提供了随机展示,隔天展示以及隔周展示等预定义的展示效果;

一旦你的访问者开始浏览首页,他们就可以看到两个首页版本之一,PHPStat Analytics会自动分配到一个或另一个给访问者。
关于用户看到的页面内容得了解一点,PHPStat Analytics 只允许用户被分组在一个单一群体里。如果您的网站已经在其他内部流程环节使用了群体,有可能上述做法不适用。这也意味着,你只能一次运行一个测试,但是这 并不是说上述方法不对。你也只会一次运行一个A/B测试,对吧?这种方法可能会过于简化你的需求,但它可以让你长期了解关系到重大决定的所有的信息。
任何工具或者方法都有其局限,AB测试也不例外。这将要讨论几个AB测试陷阱,供大家借鉴。为了方便起见,主要引用的案例或者图表是SEM管理的,但基本准则其实放之四海而皆准。
记录网站页面各个元素ID,提供每个已存在元素ID的点击量
PHPStat系统会自动给每个页面的已存在的元素id属性做记录,而我们要做AB测试也是通过页面元素的ID进行内容替换的,所以要做AB测试的页面元素必须有一个独一无二的ID。

页面元素ID标记

页面元素ID点击量数据
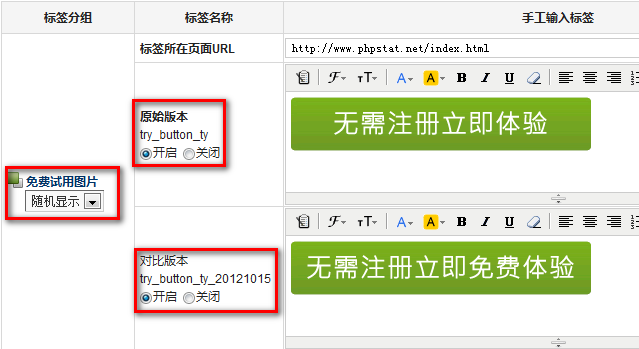
选择要进行AB测试的ID,获取原始版本的内容以及对比版本修改后的内容
.png)
选择原始版本、对比版本

选择对应的跟踪目标转化设置
系统可以自动获取原始版本以及对比版本的内容,提供了简单的html编辑器,用户可以在获取的内容基础上对对比版本进行直接修改。如果存在多个对比版本,可以控制某一个对比版本是否显示。

原始版本与对比版本内容
发布查看效果

原始版本效果图
对比版本效果图
陷阱1:轮流展示。
我们对比方案A与方案B,首先要保证两者所处的测试环境基本接近。
轮流展示,我们称之为随机展示,每个广告都会或者机率相等的展示机会(相对于访客来说),平均展示可能是广 告语A与B获得的展现量和点击量接近。
在访客A访问量网站首页,看到的版本是原始版本,那么在他后续的访问过程中,会一直展示原始版本的内容。
轮流展示是默认的AB测试设置,但测试者不能因此忘记轮流展示的原理,也即相对公平性。注意PHPStat 提示中说的是随机展示会“尽可能平均展示”。 尽可能的意思就是不保证。所以AB短期内获得的展示点击量可能差别很大。在设置AB测试 的时候,应该尽量使用新鲜的广告语,如果让历史记录较长的A与新鲜的B对抗,则A本身可能获得更多展示和点击,不完全公平。
陷阱2:统计意义。
前面提到AB测试的环境应该尽量公平。但这不是说AB组数据必须对半开,才能有效分析。实际上,我们有时候必须用现有广告语A与新增广告语B对抗,必然面对较大的数据量差异。原则上,只要数据量充分,即使两组数据总量相差比较大,还是可以获得结论的。这是因为我们分析本身就是在查看趋势,100个人对广告语 A的反馈和1000个人对广告语A的反馈,趋势可能相同。则100个人对广告语B的反馈和1000个人对广告语A的反馈,可能有可比性,只要原则上遵循轮流展示,我们可以假定这个趋势是稳定的。
A的点击1个,点击率50%, B的点击2个,点击率100%。Splittester说我们有90%的信心B的表现会比A好。你有这个信心么?我没有……个位数的数据几乎总是不可靠 的。多几个点击或者转化就会完全改变点击率或者转化率,这么大的随机因素,我不可能对太过稀疏的数据产生90%的信心。所以首先,AB测试的数据必须有足 够的量,多少是足够? 不知道,也许要加入一些主观判断,毕竟这些数据量很可能就是白花花的银子,但肯定不是个位数。其次,AB测试的数据结果差异必须有统计意义。数据量很足, 但十分接近,我们就无法判定AB到底哪一则更好。
陷阱3:漏斗之外
第三个陷阱在我看来, 是大部分AB测试实施者都忽略了的。说忽略也许不一定合适,因为我也想不出更好的办法,但这里的确有值得注意的因素。当我们测试AB两则广告语的时候,也 许会发现AB各拿1000个展现,A的点击率为2%,B的点击率为1%。A的表现比B好,则我们淘汰B,只使用A。原来的测试中,A获得 1000×2%=20个点击,B获得1000×1%=10个,总点击量为30。剔除B以后,我们期望A获得(1000+1000)×2%=40个点击。但在实战中,我们经常会发现,剔除B以后,A的点击率也下降了,(1000+1000)×1.6%=32个点击,比期望值低了一截。为什么会产生这种测试后效果下降的现象,网上讨论不少,但是没有统一的意见。我比较倾向于以下这种看法。我们习惯于把用户转化的过程用漏斗来表现。

AB测试中,我们会涉及一层或者几层,目的都是让这个漏斗变的宽些。A的漏斗比B宽,就用A取代B,但要注意,AB原来是并列的两个漏斗。B被剔除以后, 原来B漏斗中的一些用户,不一定掉入A漏斗。因为AB所传达的用户体验不同,可能有一部分B用户从A漏斗中掉出去了。通过AB测试获得更好的结果本来就是 我们的目的,在不断循环的AB测试中,我们会不断改善某一条要素的效果,但同时会付出代价,就是不断有用户从这个漏斗中掉出去。尽管从结果上来说,应该是得到了改进,但若不注意这些掉出去的用户流量,我们也浪费了很多潜在的机会。



